Intro
안녕하세요. 최근 회사에서 대용량 데이터 처리 관련 업무를 하며 GPU에 대한 관심을 갖게 되었습니다. 컴퓨터 성능에 관심이 있다면, CPU와 GPU라는 용어를 들어본 적이 있을 것입니다. 이 두 가지는 현대 컴퓨터 시스템에서 핵심적인 부품으로써 역할을 하며, 각각 고유한 기능과 특징을 갖고 있습니다. 이 글에서는 CPU와 GPU의 기본적인 기능과 차이점에 대해 설명하겠습니다.
CPU vs GPU
CPU (Central Processing Unit)란?
- CPU는 컴퓨터의 두뇌로 불리는 중앙 처리 장치입니다. 주요 기능은 컴퓨터의 모든 연산과 작업을 관리하고 조정하는 것입니다. 컴퓨터의 주요 명령어를 해석하고 실행하는 역할을 수행하여 사용자와 시스템이 원활하게 상호작용할 수 있도록 합니다.
CPU 특징
- 제어 유닛(Control Unit): 명령어를 해석하고 실행하는 데 필요한 신호 제어
- 산술 논리 연산 장치(ALU, Arithmetic Logic Unit): 산술 및 논리 연산 수행
- 캐시 메모리(Cache Memory): CPU 내부에 위치하여 빠른 데이터 접근 지원
- 스레드(Thread): 하나의 CPU 코어에서 동시에 여러 작업을 처리할 수 있는 스레드 지원
GPU (Graphics Processing Unit)란?
- GPU는 그래픽 처리에 특화된 장치로서, 3D 그래픽 및 영상 처리 작업에 사용됩니다. 초기에는 그래픽 작업을 위해 개발되었지만, 현대의 GPU는 고성능 병렬 처리 능력을 갖추고 있어 일반적인 병렬 계산 작업에도 사용됩니다. 고성능 병렬 처리 능력을 갖추고 있기 때문에 비트코인 같은 채굴 연산에 많이 사용됩니다.
GPU 특징
- 병렬 처리: 많은 코어로 구성되어 동시에 많은 연산을 병렬로 처리
- 특수 목적: 주로 그래픽 연산을 위해 설계되었지만, GPGPU(General - Purpose computing on Graphics Processing Units) 기술을 통해 일반적인 계산에도 사용
- 메모리 계층: CPU보다 큰 메모리를 가지며, 각 코어 당 작은 캐시 메모리를 갖고 있어 대규모 데이터 처리에 유리
CPU와 GPU의 차이
기능 및 용도
- CPU는 일반적인 계산, 시스템 작업, 사용자 인터페이스 등 다양한 작업을 처리하는 데 사용
- GPU는 그래픽 렌더링, 게임, 영상 편집, 인공지능, 데이터 마이닝 등 병렬 처리가 중요한 작업에 특화
코어의 구조
- CPU는 몇 개의 코어(주로 2개~16개)를 가짐
- GPU는 수백 개에서 수천 개의 코어를 가지며, 이는 대량의 데이터를 동시에 처리하는 데 유리
처리 방식
- CPU는 순차적으로 작업을 처리하며, 각 코어가 하나의 작업을 순서대로 수행
- GPU는 병렬 처리를 통해 많은 작업을 동시에 처리하며, 단일 작업을 여러 코어가 분담
속도와 성능
- CPU는 단일 코어 당 높은 성능
- GPU는 대량의 코어가 병렬 처리를 지원하여 대규모 데이터 처리에 뛰어난 성능을 보임
전력 소비
- CPU는 전력 소비가 적으며, 에너지 효율적임
- GPU는 많은 코어로 인해 전력 소비가 높을 수 있음

- CPU는 직렬 처리에 최적화된 몇 개의 코어로 구성. 반면, GPU는 병렬 처리용으로 설계되었다. 작고 효율적인 코어로 구성
- CPU는 순차적인 작업에 강점. GPU는 CPU보다 많은 코어의 수로 병렬적인 작업에 강점
마무리
최근 대용량 데이터 처리 관련 업무를 하며 GPU를 활용한 병렬 처리를 검토하고 있어서 CPU와 GPU의 간단한 차이에 대해 알아봤습니다. CPU와 GPU는 모두 컴퓨터 시스템에서 중요한 역할을 하며, 각각의 특징과 용도에 따라 다른 작업에 최적화되어 있습니다. CPU는 다양한 일반적인 작업을 처리하는 데 사용되고, GPU는 그래픽 및 대규모 병렬 처리가 필요한 작업에 특화되어 있습니다. 현대 컴퓨팅은 CPU와 GPU를 조합하여 최상의 성능과 효율성을 달성하는 것이 일반적입니다. 이러한 CPU와 GPU의 차이를 알고 소프트웨어를 개발하면 좋을 것 같습니다.
'[기타]' 카테고리의 다른 글
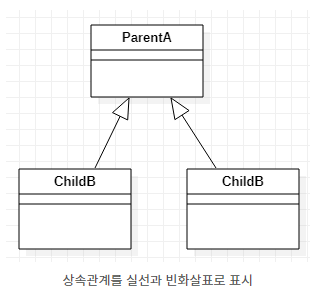
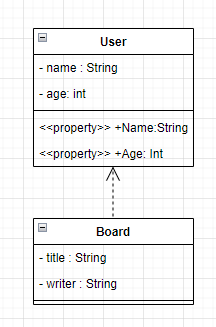
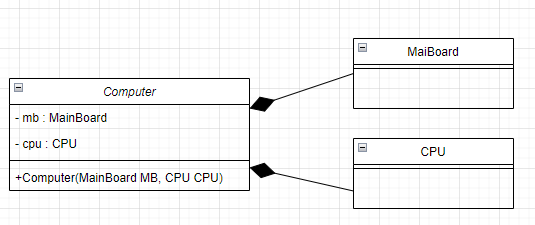
| [UML]클래스 다이어그램(Class Diagram) 작성법 (0) | 2023.07.18 |
|---|---|
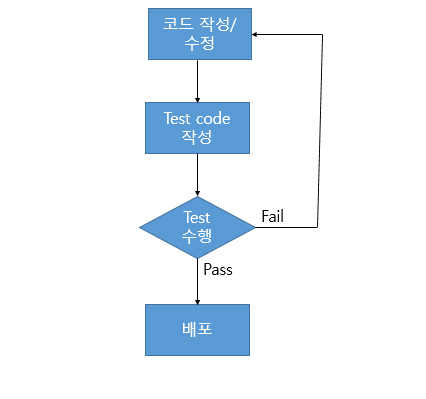
| 모범적인 개발 절차 (0) | 2021.12.11 |
| [기타 - 유닛 테스트(Unit test)란? (0) | 2021.07.25 |
| [기타 - 독시젠(Doxygen) 사용법(1)] (0) | 2021.05.31 |
| 개발자 취업 준비 추천 사이트 (구글, 원티드 ) (0) | 2021.05.23 |