Intro
안녕하세요, 지난 글에서는 소개한 HNE(Heterogeneous Network Embedding) Proximity-Preserving methods 중 random walk based approaches에 대해서 정리했는데요, 오늘은 이어서 First/Second-Order Proximity Based Approaches에 대해서 정리하겠습니다.
이번 글 역시 heterogeneous network representation learning a unified framework with survey and benchmark 논문의 내용을 정리합니다.
First/Second-Order Proximity based approaches는 비교적 간단해서, First/Second-Order Proximity based approaches에 대해서 정리한 뒤 Proximity-Preserving methods에 대한 부가적인 내용을 추가해서 정리하겠습니다.
한글표현과 영어표현이 아래와 같이 섞여서 사용될 수 있습니다
그래프, 네트워크: graph, network (두 단어는 interchangeable)
객체: node
연결: edge
Random walk based approaches vs. First/Second-Order Proximity based approaches
Random walk based approaches와 First/Second-Order Proximity Based Approaches의 차이는 무엇일까요? 제 주관적인 의견을 적어보겠습니다.
Random walk based approaches는 주로 source node로 부터 random walk를 수행해서 주어진 meta path의 모양을 갖는 path들을 찾았는데요, 이를 이용하면 여러 hop 떨어진 node사이의 관계도 고려할 수 있게 됩니다. 하지만 random walk를 수행하는 임의성이 있기 때문에, source node와 1 hop관계를 갖는 node라 할 지 라도 선택받지 못할 수 있습니다.
반면에 First/Second-Order Proximity Based Approaches의 경우에는 이름에도 적혀있듯이, 각 source node의 1 or 2 hop 관계의 모든 node를 고려합니다. 대신 이 경우 Random walk based approaches와 달리 여러 hop (>2) 관계에 있는 node들의 관계는 학습에 사용되지 않습니다.
그래서 저는 데이터만 충분하다면 여러 hop을 고려할 수 있는 random walk based 기반 방법이 더 좋지 않을까? 생각합니다.
HNE는 아니지만 개인적인 프로젝트에서 random walk based approach인 Deepwalk와 first/second-order proximity based approach인 LINE을 사용했을 때, Deepwalk이 더 좋은 성능을 보였던 경험이 있기도 합니다.
First/Second-Order Proximity based approaches
PTE
PTE는 Predictive Text Embedding의 약자로, NLP분야에서 사용되는 HNE기법입니다. PTE는 여러 개의 edge type $l \in L$이 있을 때, 각 edge type만으로 이루어진 sub graph (bipartite graph)를 만든 뒤에 각 graph별로 node embedding을 최적화합니다. objective는 아래와 같습니다.
$$\mathcal{J}=\sum_{l \in L}\sum_{u, v\in V}w_{uv}^l\log\frac{exp(e_{u}^{T}e_{v})}{\sum_{u^{'}\in V_{\phi(u)}}exp(e_{u^{'}}^{T}e_{v})}$$
$w_{uv}^l$은 type이 $l$인 edge로 연결된 node $u, v$사이의 weight입니다. 연결이 있으면 0이상의 값이, 없으면 0을 갖습니다. $V_{\phi(u)}$는 $u$와 같은 type인 node의 집합입니다. 그리고 위 objective는 결국 edge type에 대해서 aggregation이 가능해서, 아래와 같이 변형가능합니다.
$$\mathcal{J}=\sum_{u, v\in V}w_{uv}\log\frac{exp(e_{u}^{T}e_{v})}{\sum_{u^{'}\in V_{\phi(u)}}exp(e_{u^{'}}^{T}e_{v})}, w_{uv}=\sum_{l}w_{uv}^l$$
이처럼 PTE는 다소 간단한 방법이라고 볼 수 있습니다.
AspEm
AspEm는 PTE에서 한단계 발전한 모델입니다. 각 edge type별로 sub graph를 만들었던 PTE와 달리, 사전에 정의된 Aspect에 해당하는 edge type들로 이루어진 sub graph를 만들고, 이들을 각각 최적화합니다.
여기서 aspect는 사용자가 정의하기 나름인데요, 예를들어 영화 dataset인 IMDB dataset으로 만든 HN이 user, movie, actor, director, genre 5가지 edge type으로 이루어져 있다고 하겠습니다. 그러면 여기서 user가 좋아하는 actor를 위주로 embedding을 수행하고 싶다면, 우리는 node로는 user, movie, actor node type인 node를 갖고, edge는 user-movie, movie-actor를 잇는 edge type만으로 이루어진 sub graph를 추출해서 이를 최적화하면 됩니다.
edge type의 집합 $L$이 있을 때, 이것의 부분 집합으로 한 aspect $a$에 대한 edge type의 집합은 $L^a \subseteq L$입니다.
따라서 각 aspect $a$에 대한 sub graph의 embedding 최적화는 아래 objective에 따라 이루어 집니다.
$$\mathcal{J}=\sum_{l \in L^a}\frac{1}{Z_l}\sum_{u, v\in V}w_{uv}^l\log\frac{exp(e_{u, a}^{T}e_{v, a})}{\sum_{u^{'}\in V_{\phi(u)}}exp(e_{u^{'},a}^{T}e_{v,a})}$$
HEER
Heterogeneous information network Embedding via Edge Representations의 약자입니다 ㅋㅋ 되게 기네요.
HEER 역시 PTE의 변형으로, edge type별 embedding도 함께 학습하는 특징이 있습니다. objective는 아래와 같습니다.
$$\mathcal{J}=\sum_{l \in L}\sum_{u, v\in V}w_{uv}^l\log\frac{exp(\mu_l^Tg_{uv})}{\sum_{u^{'}, v^{'}\in P_l(u, v)} exp(\mu_l^Tg_{u^{'}v^{'}})}$$
$\mu_l$은 edge type $l$의 embedding이고, $g_{uv}$는 node $u, v$의 edge embedding으로 $g_{uv}=e_u \odot e_v$ 입니다. ($\odot$: element wise product)
이때, $\mu_l$의 원소를 대각성분으로 갖는 diagonal matrix $A_l$을 사용해서 아래와 같은 bilinear form으로 변형할 수 있게 됩니다.
$$\mathcal{J}=\sum_{l \in L}\sum_{u, v\in V}w_{uv}^l\log\frac{exp(e_u^T A_l e_v)}{\sum_{u^{'}, v^{'}\in P_l(u, v)} exp(e_{u^{'}}^T A_l e_{v^{'}})}$$
그 외
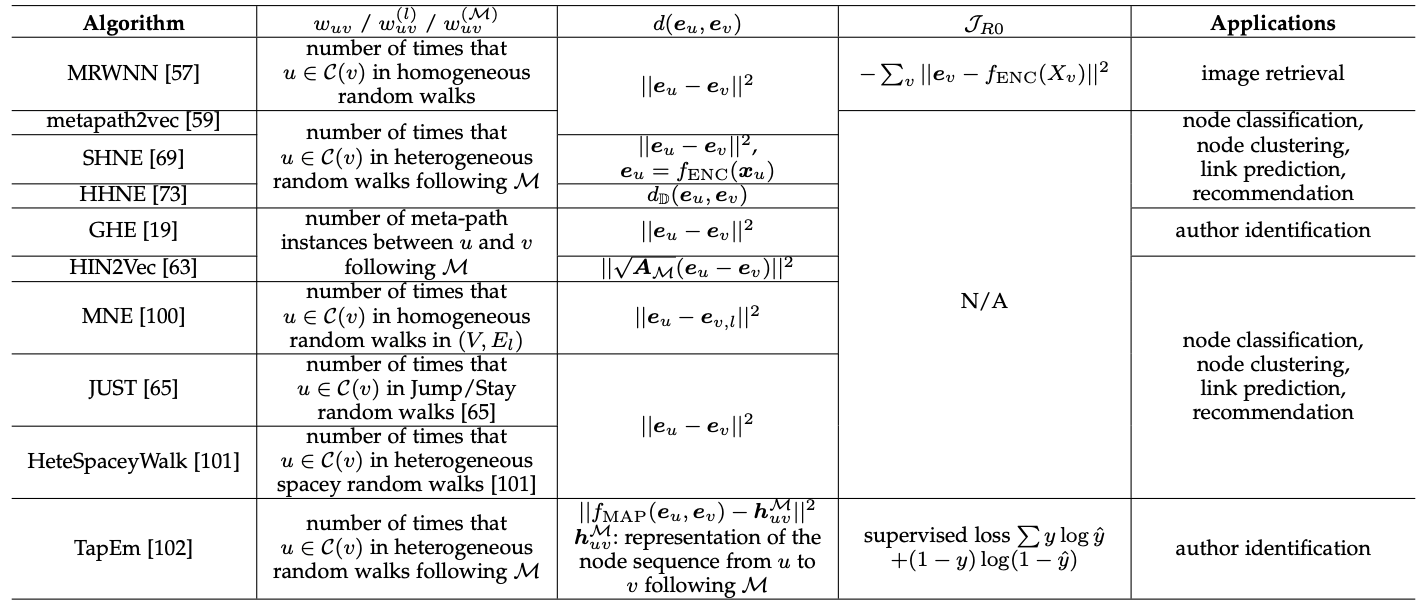
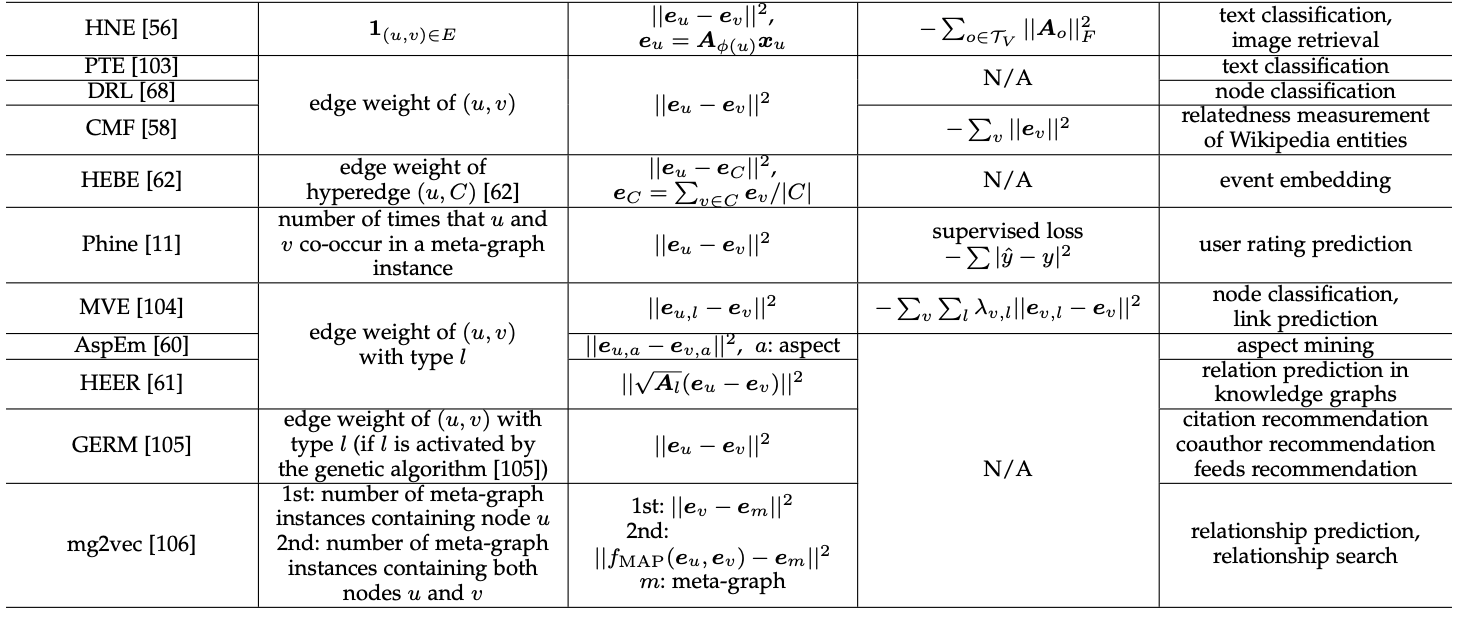
위에서 설명한 3가지 모델을 포함해서 나머지 First/Second-Order Proximity based approaches를 정리한 표를 논문에서 인용해서 첨부하겠습니다.
Network Smoothness Enforcement
여기까지 Proximity-Preserving methods에 대해서 대략적인 정리를 해봤습니다. 논문의 저자들은 흥미로운 insight를 제시했는데요, 우선 여러 모델의 objective는 아래와 같이 일반화 할 수 있습니다.
$$max \mathcal{J}=\sum_{u, v\in V}w_{uv}\log\frac{s(u, v)}{\sum_{u^{'}}s(u', v)} + \mathcal{J}_{R_0}$$
$s(u, v)$는 node $u, v$의 유사도를 나타내는 함수로, $f(e_u)^Tf(e_v)$로 나타낼 수 있습니다. 대부분의 method는 $f$를 항등 함수로 사용하겠지만, HIN2Vec는 $f(e_u)=\sqrt{M}e_u$, HEER은 $f(e_u)=\sqrt{A_l}e_u$이 될 수 있습니다. (왜 bilinear form으로 변형했는지 알 수 있는 대목입니다!)
위 식을 negative sampling 형태로 변환 한뒤, 정리를 하면, $\mathcal{J}_{R_0}$외에 2가지 regulization term을 발견할 수 있습니다.

마지막 수식을 보면, 결국 대부분의 HNE 모델의 objective는 1) 두 node $u, v$의 embedding이 유사해지고 (빨간 박스 첫번째 줄), 2) $u, v$의 embedding의 크기가 0보다 커지게 하고, (빨간 박스 두번째 줄) 3) $u$가 아닌 나머지 $u^{'}$에 대해서는 v와 유사해지지 않도록 (빨간 박스 세번째 줄) 최적화가 됩니다.
1)은 objective의 주 목적이고, 2)는 $u, v$의 embedding이 모두 zero vector 되지 않도록 하고, 3)은 모든 node의 embedding이 동일해지지 않도록 하는 역할을 하게 됩니다.
단순히 수식만 재배열 했을 뿐인데 이런 insight을 얻을 수 있네요.
마무리
오늘은 여러 First/Second-Order Proximity based approaches를 정리하고, 대부분의 HNE 모델들이 갖는 objective에 대한 insight을 정리해봤습니다.
사실 proximity-preserving 모델들은 shallow하다고 볼 수 있습니다. 최적화학 모델의 layer가 1개만 있는 거죠. 그러다 보니 non-linearity가 부족한 특징이 있습니다.
다음에는 조금 더 deep한 모델들을 사용하는, Message-passing methods에 대해서 정리하겠습니다.
감사합니다!
References
Heterogeneous Network Representation Learning: A Unified Framework with Survey and Benchmark
PTE: Predictive Text Embedding through Large-scale Heterogeneous Text Networks
ASPEM: Embedding Learning by Aspects in Heterogeneous Information Networks
Easing Embedding Learning by Comprehensive Transcription of Heterogeneous Information Networks
'[Machine Learning]' 카테고리의 다른 글
| HNE - proximity preserving methods(1) (0) | 2021.09.27 |
|---|---|
| HNE (Heterogeneous Network Embedding) - 소개 (0) | 2021.08.31 |
| AWS (2) Services (0) | 2021.05.12 |
| AWS (1) 시작하기 (0) | 2021.04.27 |