Intro
안녕하세요, 오늘은 python의 Mixin에 대해서 정리해보고, 제가 이해하는데 도움이 됐던 코드를 소개해드리겠습니다.
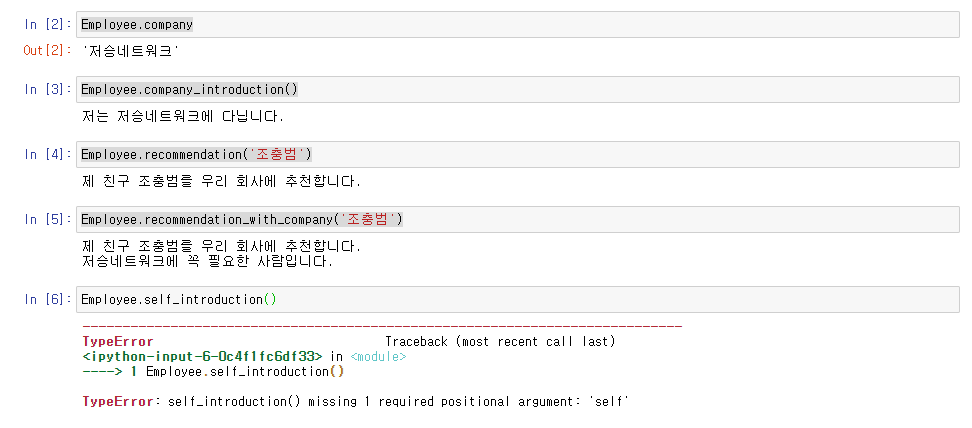
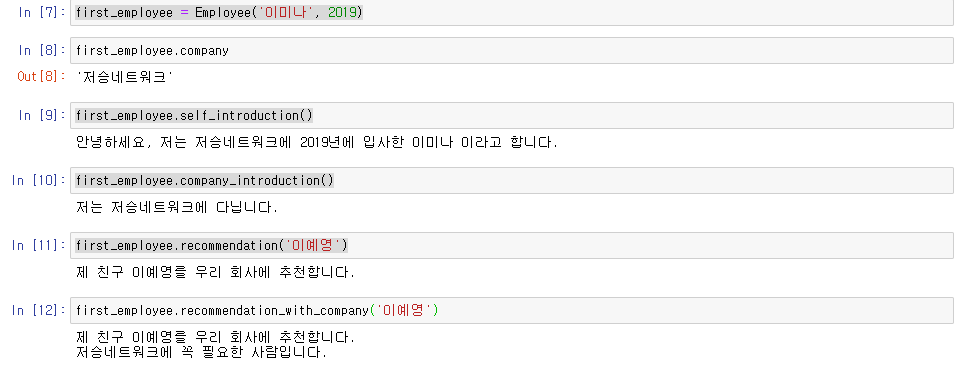
Mixin vs. Inheritance (상속)
Mixin은 Inheritance의 한 종류 입니다. 하지만 쓰임에 있어서 일반적인 inheritance와 미묘하게 다른 차이가 있습니다.
간단하게 말하자면 일반적인 inheritance에서는 핵심 기능을 부모 class에, 부가적인 기능을 자식 class에 구현합니다.
예를 들면 부모 class는 Car, 자식 class는 SportsCar, Truck 등이 될 수 있습니다.
다만 mixin은 어떤 핵심 기능을 구현한 class가 부가적인 기능을 추가하기 위해 특정 클래스를 상속 받습니다.
마치 닭과 달걀의 관계와 유사하다고 느껴지실 수 있겠지만, mixin은 다양한 기능이 조합되어야 하는 문자열 처리, 또는 프레임워크를 사용할 때 주로 쓰입니다.
아래 두 가지 예시 코드를 보겠습니다.
Tokenizer with Mixin
주어진 문자열을 -을 기준으로 분리해주는 tokenizer인 BaseTokenizer 클래스가 있습니다. 이를 상속한 Tokenizer 클래스가 있는데, 여기에 각 token을 대문자로 바꿔주는 기능을 추가하고 싶습니다. 즉 주기능은 tokenize인데, 여기에 대문자 변환 기능을 추가하고 싶은 것이죠.
여기서 의문이 생길 수 있습니다. 그냥 Tokenizer 클래스에 대문자 변화 method를 추가해주면 되니까요.
하지만, tokenizer는 tokenizer여야 합니다.
따라서 클래스 안에 부가적인 이것 저것 기능을 구현하기 보다는 필요한 기능이 구현된 클래스를 상속하는게 더 좋은 코드가 되는 것이죠.
아래 예시 코드는 파이썬 클린 코드의 코드를 가져왔습니다.
class BaseTokenizer:
def __init__(self, str_token):
self.str_token = str_token
def __iter__(self):
yield from self.str_token.split("-")
class UpperIterableMixin:
def __iter__(self):
return map(str.upper, super().__iter__())
class Tokenizer(UpperIterableMixin, BaseTokenizer):
pass
tokens = Tokenizer("28a2320b-fd3f-4627-9792-a2b38e3c46b0")
list(tokens)
>> ['28A2320B', 'FD3F', '4627', '9792', 'A2B38E3C46B0']이와 같이, UpperIterableMixin을 상속함으로써 클래스에 추가적인 기능을 지원해주는 것을 Mixin이라고 할 수 있습니다.
Database with Mixin
아래 코드는 마이크로소프트에서 제공하는 Mixin 소개 영상의 코드를 가져왔습니다.
우리가 어떤 framework를 사용하려고 합니다.framework는 다양한 기능을 제공하죠, 특히 database에 접근할 때는, database에 접속하고, 관련 log를 남겨야 합니다.
하지만 앞서 말했듯이, 접속과 로깅은 database만의 기능이 아닙니다. database는 데이터만 잘 가져오고, 저장하면 됩니다. 따라서 이러한 기타 기능들을 추가하기 위해서 mixin을 사용할 수 있습니다. 아래 코드의 Loggable과 Connection이 해당합니다.
Database를 다루는 framework는 이러한 기능이 구현되었는지 확인한 뒤, 기능을 수행합니다.
class Loggable:
def __init__(self):
self.title = ''
def log(self):
print('Log message from ' + self.title)
class Connection:
def __init__(self):
self.server = ''
def connect(self):
print('Connecting to database on ' + self.server)
class SqlDatabase(Connection, Loggable):
def __init__(self):
self.title = 'Sql Connection Demo'
self.server = 'Some_Server'
def framework(item):
if isinstance(item, Connection):
item.connect()
if isinstance(item, Loggable):
item.log()
sql_connection = SqlDatabase()
framework(sql_connection)
>> Connecting to database on Some_Server
>> Log message from Sql Connection Demo마무리
오늘은 python의 mixin에 대해서 정리했습니다. 글 읽어주셔서 감사합니다!
References
'[Python]' 카테고리의 다른 글
| [Python] 강건한 프로그래밍을 위한 type hint (feat. typing 모듈) (1) | 2021.07.25 |
|---|---|
| [Python] timeit 모듈과 pandas함수들의 속도 비교 테스트 (0) | 2021.07.18 |
| [Python] Decorator(4) - dataclass, functools (0) | 2021.07.04 |
| [Python] Decorator(3) - @classmethod, @staticmethod (0) | 2021.06.28 |
| [Python] Decorator (2) - @property (0) | 2021.06.20 |