반응형
Intro
안녕하세요. 이번에는 vector의 tuple요소로 sort하는 방법에 대해 포스팅 하겠습니다.
vector의 tuple값으로 sort
프로그램을 하다 보면 vector에 tuple로 묶어서 데이터를 저장할 때 sort방법입니다.
#include <iostream>
#include <vector>
#include <algorithm>
#include <tuple>
using namespace std;
static bool CmpName(tuple<string, string, int> &v1, tuple<string, string, int> &v2)
{
return get<0>(v1) > get<0>(v2);
}
int main(void)
{
std::vector<tuple <string, string, int>> v;
v.push_back(make_tuple("workid 1", "2021-10-27 08:20:18", 3));
v.push_back(make_tuple("workid 2", "2021-10-28 09:22:18", 5));
v.push_back(make_tuple("workid 3", "2021-10-29 10:18:18", 7));
v.push_back(make_tuple("workid 5", "2021-10-27 14:32:18", 1));
v.push_back(make_tuple("workid 8", "2021-10-27 14:47:18", 2));
v.push_back(make_tuple("workid 6", "2021-10-30 14:36:18", 6));
v.push_back(make_tuple("workid 4", "2021-10-29 11:12:18", 4));
v.push_back(make_tuple("workid 9", "2021-10-26 08:20:18", 8));
v.push_back(make_tuple("workid 7", "2021-10-27 14:37:18", 5));
sort(v.begin(), v.end());
for (int i = 0; i < v.size(); i++)
cout << get<0>(v[i]) << "\t" << get<1>(v[i]) << "\t" << get<2>(v[i]) << endl;
return 0;
}결과
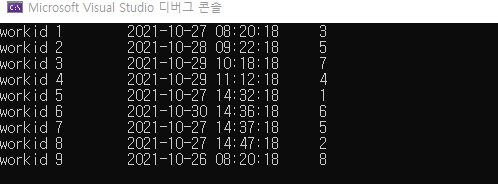
일반적으로 sort를 하면 tuple의 첫번째 값에 의해 오름차순 sort가 됩니다. 하지만 제가 원하는건 tuple의 다른 요소로 sort하는 방법입니다.
#include <iostream>
#include <vector>
#include <algorithm>
#include <tuple>
using namespace std;
static bool CmpName(tuple<string, string, int> &v1, tuple<string, string, int> &v2)
{
return get<2>(v1) < get<2>(v2);//tuple 3번째 값으로 비교
}
int main(void)
{
std::vector<tuple <string, string, int>> v;
v.push_back(make_tuple("workid 1", "2021-10-27 08:20:18", 3));
v.push_back(make_tuple("workid 2", "2021-10-28 09:22:18", 5));
v.push_back(make_tuple("workid 3", "2021-10-29 10:18:18", 7));
v.push_back(make_tuple("workid 5", "2021-10-27 14:32:18", 1));
v.push_back(make_tuple("workid 8", "2021-10-27 14:47:18", 2));
v.push_back(make_tuple("workid 6", "2021-10-30 14:36:18", 6));
v.push_back(make_tuple("workid 4", "2021-10-29 11:12:18", 4));
v.push_back(make_tuple("workid 9", "2021-10-26 08:20:18", 8));
v.push_back(make_tuple("workid 7", "2021-10-27 14:37:18", 5));
sort(v.begin(), v.end(), CmpName);
for (int i = 0; i < v.size(); i++)
cout << get<0>(v[i]) << "\t" << get<1>(v[i]) << "\t" << get<2>(v[i]) << endl;
return 0;
}결과
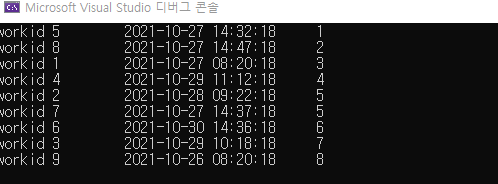
sort에 CmpName를 추가 하여 tuple의 3번째 값으로 오름 차순 정렬을 했습니다. 내림차순은 CmpName함수에서 return get<2>(v1) < get<2>(v2); 값을 return get<2>(v1) > get<2>(v2); 부등호를 바꿔 주면 됩니다.
마무리
이상으로 포스터를 마치겠습니다. 요즘 회사에서 바빠서 포스팅을 많이 올리지 못했는데 자주 올리도록 노력해 보겠습니다.
감사합니다.
반응형
'[C++ STL]' 카테고리의 다른 글
| [C++ Stl - 하드웨어 스레드 개수 알기] (0) | 2021.12.26 |
|---|---|
| [C++ STL - 스레드(thread)(1)] (0) | 2021.12.26 |
| [C++ For문에서 Vector erase 사용법 (0) | 2021.11.01 |
| [C++ STL - chrono(시간 측정)] (0) | 2021.06.30 |
| [C++ STL - forward_list] (0) | 2021.06.24 |