안녕하세요, 이번에 MySQL을 공부할 일이 생겨서, 정리한 내용 공유할 겸 글을 써보겠습니다.
명령어는 검은색, 변수 이름은 파란색으로 표시했습니다.
DB 및 TABLE 조회
CREATE DATABASE database-name; - DATABASE 생성
SHOW DATABASES; - 생성되어 있는 DATABASE 조회
SELECT DATABASE(); - 현재 사용중인 DATABASE 확인
USE database-name; - 사용할 DATABASE 선택
SHOW TABLES; - 현재 DATABASE의 TABLE확인
DESC table-name; - 특정 TABLE의 scheme 확인
TABLE 관리
TABLE 생성
CREATE TABLE IF NOT EXISTS table-name ( id INT NOT NULL PRIMARY KEY AUTO_INCREMENT, str1 VARCHAR(20), ## 20자리 가변 문자열 (메모리 효율 good, 속도 bad) str2 CHAR(1), ## 1자리 고정 문자열 (메모리 효율 bad, 속도 good) int1 INT(5), ## 5자리 정수 date1 DATE); ## yyyy-mm-dd A. 그 외 자료형: BOOL, DECIMAL, FLOAT, REAL, DOUBLE 등 B. 정확한 소수점 저장을 위해서는 DECIMAL사용 (고정소수점)
MySQL constraints 종류 A. NOT NULL, UNIQUE, PRIMARY KEY, FOREIGN KEY, CHECK, DEFAULT
다른 테이블 값 복사 CREATE TABLE IF NOT EXISTS new-table-name AS SELECT * FROM table-name;
TABLE 삭제
DROP TABLE IF EXIST table-name;
TABLE 수정
ALTER TABLE IF EXIST table-name [수정 내용];
Instance 추가
모든 변수에 대해서 추가 INSERT INTO table-name VALUES (NULL, "apple", "melon",100, '2012-04-14');
특정 변수에 대해서만 추가 (나머지는 null됨) INSERT INTO table-name ('id','str1') VALUES (NULL, "apple");
여러 개 추가 INSERT INTO table-name VALUES ("apple", "melon",100, '2012-04-14'), ("car", "cat",100, '2012-04-14'), ("ben", "chi",100, '2012-04-14');
Instance 삭제
DELETE FROM customers ##data를 삭제한 table 선택 WHERE country = 'France' ##삭제할 data의 조건 명시, 안하면 모두 삭제 ORDER BY creditLimit ##삭제 대상 instance를 creditLimit으로 정렬 LIMIT 5; ##creditLimit이 가장 낮은 5개의 instance 삭제
Instance 수정
A. UPDATE table-name SET [수정 사항] WHERE [수정 대상];
마무리
사실 이것만 보고는 감을 익히기 어려울 겁니다. 이를 참고해서 MySQL문제를 풀어보시는게 좋을 거 같습니다.
다음에는 본격적인, TABLE에서 정보를 추출하기 위한 Query에 대해서 정리하겠습니다!
오늘은 제가 영상 처리할 때 사용하는 OpenCV에 대한 내용과 Visual studio의 연동 방법에 대해 포스팅하겠습니다.
OpenCV란?
OpenCV(Open Source Computer Vision)은 영상 처리에 대한 무료 오픈소스 라이브러리입니다.
OpenCV는 실시간 영상처리를 위해 인텔(Intel)에서 개발하였고, 실시간 이미지 프로세싱을 중점을 두고 있습니다.
C/C++ 프로그래밍 언어로 개발되었으며 파이썬 , 자바 및 매트랩 / OCTAVE에 바인딩되어 프로그래머에게 개발 환경을 지원합니다.
OpenCV는 학교 교육이나, 회사에서 상업용으로 제품을 만들어도 무료이기 때문에 많은 사람들이 활용하는 장점이 있습니다. 그리고 복잡한 알고리즘이나 계산식을 라이브러리로 구현을 했기 때문에 사용자 입장에서는 편하게 사용할 수 있습니다. 실무에서 C++이나 Python에서 정말 많이 사용됩니다.
Visual studio 2019와 OpenCV를 연동해 보겠습니다. OpenCV버전은 4.5.2입니다.
Opencv & Visual studio 연동하기
Visual studio로 프로젝트 생성(프로젝트는 그냥 빈 프로젝트로 만들었습니다. MFC나 DLL 생성하거나 기타 프로젝트도 동일한 방법으로 OpenCV 연동하면 됩니다.)
)
헤더 파일 복사 및 경로 설정(OpenCV 다운로드한 폴더에서 opencv/build/include 폴더를 복사하여 프로젝트에 넣어 줍니다. 절대 경로로 사용해도 되긴 하는데 보통은 프로젝트 안에 상대 경로로 넣어서 사용합니다. 프로젝트(P)-> 속성(P)->C/C++ -> 모든 옵션 or 일반 -> 추가 포함 디렉터리에 .\include\opencv2;를 추가해 줍니다)
)
)
lib 폴더 프로젝트 폴더에 복사합니다.(opencv\build\x64\vc15\lib 폴더를 프로젝트 폴더에 복사) 프로젝트(P)-> 속성(P)->링커->일반 or 모든 옵션 -> 추가 라이브러리 디렉터리에 .\lib 추가. 그다음에 프로젝트(P)-> 속성(P)->링커->입력->추가 종속성->opencv_world452d.lib를 추가해줍니다. Debug모드일 때는 opencv_world452d.lib, Release일 때는 opencv_world452.lib를 추가해 줍니다.
)
)
마지막으로 opencv\build\x64\vc15\bin 경로에서 Debug모드 일 때는 opencv_world452d.dll파일을 프로젝트의 Debug 실행 파일이 있는 위치에 넣어줍니다. Release에는 opencv_world452.dll파일을 프로젝트의 Release 폴더에 넣어줍니다. 그러면 연동이 끝납니다.
OpenCV를 연동할 때는 Visual Studio와 OpenCV 버전을 맞춰줘야 합니다. 그리고 Debug모드 Release모드를 고려해서 lib파일과 dll파일을 설정해야 합니다.
디자인 패턴은 소프트웨어 기술 면접에 자주 나오는 질문 중 하나입니다. 보통 기술면접에서 특정 상황을 물어본다음에 어떤 디자인 패턴을 사용하면 좋을까요? 이런 식으로 질문을 하거나 싱글턴 패턴이 뭔가요?처럼 특정 디자인 패턴을 물어보는 경우가 많습니다. 디자인 모든 디자인 패턴을 완벽하게 숙지하지 못하더라도 특정 상황에서 자주 쓰이는 디자인 패턴의 종류와 역할을 알면 면접에서 좋은 답변을 할 수 있습니다. 그럼 디자인 패턴에 대한 포스팅을 시작하겠습니다.
누군가는 이미 제가 가진 어려움을 경험했을 것입니다. 그리고 그 누군가는 제가 가진 어려운 경험을 이미 해결했을 것입니다. 우리는 그 문제를 해결했던 다른 개발자들의 지혜와 교훈을 배우고 익혀야 합니다.
즉, 소프트웨어 공학에서 디자인 패턴이란 프로그램을 개발하는 과정에서 빈번하게 발생하는 애로사항이나 디자인 상의 문제를 정리해서 상황에 따라 간편하게 적용해서 쓸 수 있는 패턴 형태로 만든 것입니다. 디자인 패턴을 잘 활용하면 단지 코드의 재사용뿐만 아니라, 더 큰 그림을 그리기 위한 디자인으로 재사용할 수 있습니다.
패턴이란 특정 컨텍스트 내에서 주어진 문제에 대한 해결책이다. 컨텍스트(context) : 패턴이 적용되는 상황. 반복적으로 일어날 수 있는 상황. 문제(problem) : 컨텍스트 내에서 이루고자 하는 목적 해결책(solution) : 누구든지 적용해서 일련의 제약조건 내에서 목적을 달성할 수 있는 일반적인 디자인을 의미
디자인 패턴 종류
1. 생성 관련 패턴(Creational Patterns) : 객체 인스턴트 생성을 위한 패턴으로 클라이언트와 그 클라이언트에서 생성해야 할 객체 인스턴스 사이의 연결을 끊어주는 패턴.
빌더(Builder)
싱글턴(Singleton)
팩토리 메소드(Factory Methods)
프로토타입(Prototype)
추상 팩토리 메소드(Abstract Factory Methods)
2. 구조 관련 패턴 (Structural Patterns) : 클래스 및 객체들의 구성을 통해 더 큰 구조로 만들 수 있게 해주는 패턴.
데코레이터(Decorator)
플라이웨이트(Flyweight)
컴포지트(Composite)
어댑터(Adapter)
브리지(Bridge)
퍼사드(Facade)
프록시(Proxy)
3. 행동 관련 패턴 (Structural Patterns) : 클래스와 객체들의 상호작용하는 방법 및 역할을 분담하는 방법에 관련된 패턴.
템플릿 메소드(Template Method)
인터프리터(Interpreter)
역할 사슬(Chain of Responsibility)
커맨드(Command)
비지터(Visitor)
미디에이터(Mediator)
이터레이터(Iterator)
메멘토(Memento)
옵저버(Observer)
스테이트(State)
스트래티지(Strategy)
클래스와 객체에 따른 패턴 분류 방법
1. 클래스 패턴 (Class Patterns) : 클래스 사이의 관계를 상속을 통해 정의. 클래스 패턴은 컴파일 시에 관계가 결정됨.
템플릿 메소드(Template Method)
팩토리 메소드 (Factory Methods)
어댑터(Adapter)
인터프리터(Interpreter)
2. 객체 패턴 (Object Patterns) : 객체 사이의 관계를 다루며, 객체 사이의 관계는 보통 구성을 통해 정의됨. 객체 패턴에서 일반적으로 실행 중에 관계가 생성되기 때문에 더 동적이고 유연함.
컴포지트(Composite)
데코레이터(Decorator)
프록시(Proxy)
스트래티지(Strategy)
브리지(Bridge)
플라이웨이트(Flyweight)
추상 팩토리 메소드 (Abstract Factory Methods)
퍼사드(Facade)
역할 사슬(Chain of Responsibility)
미디에이터(Mediator)
비지터(Visitor)
커맨드(Command)
프로토타입(Prototype)
싱글턴(Singleton)
이터레이터(Iterator)
메멘토(Memento)
옵저버(Observer)
스테이트(State)
빌더(Builder)
마무리
마지막으로 오늘은 디자인 패턴이 무엇인지와 디자인 패턴의 종류에 대해 알아봤습니다. 디자인 패턴을 정리하다 보니 설명도 없이 종류에 대해 길게 적어 놨는데... 다음 시간부터는 자주 쓰이는 디자인 패턴에 대해 자세히 탐구하는 시간을 가져 보겠습니다.
오늘은 C++ STL 중에 가장 많이 쓰이게 될지도 모르는? auto라는 키워드에 대해 설명하겠습니다.
auto
C++에서 auto는 변수를 정의할 때 명시적으로 형을 지정해 주지 않아도 됩니다.
왜냐하면 auto 변수는 초기화할 때 초기화 값에 따라서 자동으로 형을 결정해 주기 때문입니다.
즉, auto는 변수를 정의할 때 명시적으로 형을 지정하지 않고 컴파일러가 형을 자동으로 지정해주는 키워드입니다.
하지만 auto는 지역변수에서만 사용이 가능합니다.
클래스의 멤버 변수, 전역 변수, 함수의 인자로의 사용은 불가능합니다.
그리고 선언과 동시에 초기화를 시켜줘야 합니다.
그렇지 않으면 auto의 형식을 추론할 수 없다는 오류 메시지가 뜨게 됩니다.
정적 언어 vs 동적 언어의 차이 최근에 JavaScript, Ruby, Python 같은 스크립트 언어가 인기가 많습니다. 실제 개발에서 많이 쓰이기도 합니다. 이러한 스크립트 언어를 동적 언어라고 합니다. 이와 반대로 C, C++, C#, Java, Objective-C를 정적 언어라고 합니다. 정적 언어는 변수형을 선언하거나 정의할 때 명시적으로 자료형을 지정해야 합니다. ex) int a, double b, float c. 하지만 동적 언어는 자료형을 명시적으로 지정하지 않아도 됩니다. auto를 사용하면 스크립트 언어처럼 자료형을 지정하지 않아도 됩니다.
Example
#include<iostream>
int main()
{
auto Name = "Anabebe";
std::cout << Name << std::endl;
auto nNum = 100;
std::cout << nNum << std::endl;
auto fNum = 100.99;
std::cout << fNum << std::endl;
return 0;
}
마무리
auto를 사용하면 프로그래밍이 이전보다 훨씬 더 간편해집니다.
STL의 컨테이너를 사용할 때 귀찮은 부분 중 하나가 반복자를 정의할 때 반복자를 길게 적어야 할 때가 있습니다.
이때 typedef를 사용하여 불편함을 감소시켜야 하지만 auto를 사용하면 불편함을 없앨 수 있습니다.
하지만 auto는 만능이 아닙니다. 같이 협업하는 사람 중에 auto를 아주 사랑하는 동료가 있었는데 모든 변수에 auto를 남발하다 보니 자료형을 정확히 알아야 하는 경우 찾기가 힘들었습니다.
표준 정규분포를 따르지 않는 정규분포와 다른 분포들도 분포를 이루는 각 값에서 평균을 빼고, 표준편차로 나눔으로써 $\mu=0, \sigma=1$인 상태로 변환할 수 있습니다.
이런 과정을 표준화(standardization)이라고 합니다.
이때 표준화된 분포의 각 값을 z-score라고 합니다.
$$z=\frac{x-\mu}{\sigma}$$
표준화는 분포의 모양을 바꾸지 않는 변환이기 때문에, 아래와 같은 목적으로 사용될 수 있습니다.
두 분포의 모양 비교 데이터 전처리 (scaling) 정규성 검정
정규성 검정
정규성 검정(normality test)은 주어진 분포가 정규분포를 따르는지 확인하기 위한 방법입니다. 이는 가설 검정 기법인 t-test, ANOVA가 검정하려는 데이터의 분포가 정규성을 갖는다는 가정하에 사용되기 때문에, 해당 방법들을 적용할 수 있는지 여부를 알기 위해서 사용됩니다.
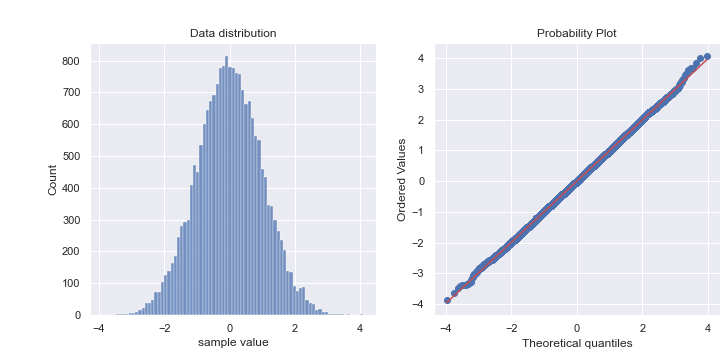
정규성 검정을위한 첫번째 방법으로, Q-Qplot(Quantile-Quantile plot)이 있습니다. Q-Qplot은 두 분포가 얼마나 유사한지를 보여주는 일반적인 graphical method입니다.
이때 정규성검정을 하고자 하는 분포를 표준화한 뒤, 표준 정규분포와의 Q-Qplot을 그리면, 해당 분포가 정규분포를 갖는지 알 수 있습니다.
여기까지 봤을 때는 이들이 포아송 분포와 무슨 상관이 있을까 싶을겁니다. 지수분포는 감마분포의 특수한 경우고, 특히 포아송 분포와 관련이 깊습니다.
포아송 분포는 일정 시간, 공간에서 특정한 수의 사건이 발생할 확률을 계산하는데 사용되죠, 이때 확률변수는 사건발생 수입니다. 반면에, 지수분포는 사건 발생 수가 아닌 다음 사건이 일어날 때까지의 시간을 확률변수로 갖습니다. 이렇기 때문에 포아송 분포는 이산 확률분포, 지수분포는 연속형 확률분포인거죠!
그러면 포아송 분포를 이용해서 지수분포를 유도해보겠습니다. $x$시간 내에 첫번째 사건이 발생할 확률을 계산해봅니다.
$x$시간 내에 첫번째 사건이 발생할 확률은, 1에서 $x$시간 내에 첫번째 사건이 발생하지 않을 확률을 빼는 것과 같습니다. 이는 $x$시간 동안 단 한번도 사건이 발생하지 않을 확률 $p(0;\lambda x)$과 같습니다.
포아송 분포에 의해
$$P(X>x)=p(0;\lambda x)=e^{-\lambda x},$$
우리가 구하고자 하는 확률은 아래와 같은 $X$의 누적분포함수가 됩니다.
$$P(0\leq X \leq x)=1-e^{-\lambda x}$$
연속형 확률변수의 누적분포함수를 미분하면 확률밀도함수가 되기 때문에, 이를 미분한 결과는 $\lambda=\frac{1}{\beta}$인 지수분포의 확률밀도함수와 같아집니다.
$$f(x)=\lambda e^{-\lambda x}$$
이렇게, 지수분포의 모수 $\beta$는 포아송 분포의 모수인 $\lambda$와 역수 관계임이 확인되었습니다. 그렇다면, 우리는 $\beta$를 평균사건발생간격으로 볼 수 있습니다. 비록 우리가 구한건 최조 사건 발생까지의 시간이지만, 단위시간 당 평균 사건 발생 수($\lambda$)는 시간에 관계없이 동일하기 때문에 이런 해석이 가능합니다.
지수분포와 감마분포의 관계
지수분포는 감마분포의$\alpha$가 1일 때의 특수한 경우고, 평균사건발생간격 $\beta$를 모수로 갖는 사건발생간격의 확률분포입니다.
그렇다면 $\alpha$가 1보다 큰 경우인 감마분포는 무엇을 의미할까요? 감마분포는 평균사건발생간격이 $\beta$인 사건이 $\alpha$번 발생할 때까지의 시간의 확률분포입니다.
마무리
이번에는 포아송 분포와 관련이 깊은 지수분포, 감마분포에 대해서 알아봤습니다.
세 분포를 한 문장씩 정리하면 아래와 같습니다.
포아송 분포: 단위시간, 단위범위 당 사건 발생횟수 $\lambda$가 주어졌을 때, 주어진 시간 동안 포아송 사건이 $x$번 발생할 확률의 분포
지수분포: 평균사건발생간격 $\beta(=\frac{1}{\lambda})$가 주어졌을 때, 시간 $x$내에 포아송 사건이 발생할 확률의 분포
감마분포: 평균사건발생간격 $\beta$가 주어졌을 때, 시간 $x$내에 포아송 사건이 $\alpha$번 발생할 확률의 분포
감마분포에 사용된 감마함수는 카이제곱분포, 베타분포에도 사용됩니다. 특히, 카이제곱분포는 감마분포의 모수인 $\alpha, \beta$가 각각 $v/2, 2$일 때의 특수한 형태로, 통계적 추론에서 많이 쓰입니다.
한 번 시행할 때 마다 성공 혹은 실패, 1 또는 0의 값을 갖는 작업이 있다고 해보겠습니다. 이 작업은 동전 던지기, 수술 성공 여부, 사용자의 상품 구매 여부 등 여러가지 상황으로 볼 수 있습니다.
각 시행은 독립이고, 매 시행의 성공확률이 동일한 상수일 때, 우리는 각 시행을 베르누이 시행(Beronoulli trial)이라고 하고, 이 시행을 반복하는 과정을 베르누이 과정(Bernoulli process)라고 합니다.
$n$번의 베르누이 시행을 진행했을 때 성공 (또는 1) 횟수 $X$를 이항확률변수(binomial random variable)라고 합니다. 그리고 $X$의 확률분포를 이항분포(binomial distribution)라고 합니다.
이항분포는 $b(x;n,p)$로 표현할 수 있는데요, 성공확률이 $p$인 베르누이 시행을 $n$번 했을 때, 성공 횟수 $x$의 확률분포(이항분포)를 의미합니다.
$x$번 성공한다는 것은 곧 $n-x$번 실패한다는 뜻이고, 이는 $x$번 성공하고 $n-x$번 실패할 확률과 같습니다. 이때 성공과 실패의 순서는 상관이 없습니다. 따라서 이항분포의 각 $x$의 확률은 아래와 같이 구할 수 있습니다.
$$b(x;n,p)={n \choose x}p^xq^{n-x}$$
$${n \choose x}=\frac{n!}{x!(n-x)!},\ q=1-p$$
이산형 균일분포의 평균과 분산은 아래와 같습니다.
$$\mu = np\qquad\sigma^2 = npq$$
음이항분포
이항분포에서는 성공확률이 $p$인 베르누이 시행을 $n$번 했을 때, 성공 횟수가 $x$번일 확률을 계산할 수 있었습니다.
하지만 우리는 $\alpha$번째 성공이 $x$번째 시행에서 일어날 확률을 알고싶을 수 있습니다. 한화 이글스가 5번째 경기에서 2번째 승리를 할 확률 같은거죠.
이런 종류의 실험을 음이항실험(negative binomial experiments)이라 합니다. 이때 $\alpha$번째 성공이 이루어질 때 까지의 시행 횟수 $x$를 음이항확률변수(negative binomial random variable), $x$의 확률분포가 음이항분포(negative binomial distribution)입니다.
한화 이글스가 매 경기에서 승리할 확률이 $\frac{1}{5}$라고 가정했을 때, 5번의 경기중 2번 승리할 확률은 아래와 같습니다.
주의: 서로 독립인 두 변수의 공분산과 상관계수는 0이지만, 역은 성립하지 않습니다. 왜냐하면 앞서 설명한 상관관계는 두 변수 사이의 선형 관계만을 나타내기 때문입니다. 즉, 일차식으로 표현할 수 있는 범위에서의 상관관계를 알 수 있는 겁니다. 독립은 한 변수의 변화가 다른 변수의 변화에 영향을 끼치지 않는 것을 의미하므로, 두 변수가 선형 관계뿐만 아니라 다항식, 지수, log관계 등 어떤 관계도 갖지 않는 것을 의미합니다.
import numpy as np
import pandas as pd
import seaborn as sns
# AT&T와 버라이즌의 일별 주식가격 등락률 정보 로드
save_path = "./img/2021-02-23"
sp500_px_df = pd.read_csv('data/sp500_data.csv') # S&P500에 있는 회사의 일별 주식 등락 정보
sp500_px_df.rename(columns={'Unnamed: 0': 'Dates'},inplace=True)
atnt = 'T' # AT&T 종목코드
verizon = 'VZ'# 버라이즌 종목코드
{% endhighlight %}
S&P500에 있는 AT&T와 버라이즌이라는 회사의 주가 등락률의 상관관계를 분석해보겠습니다. 유명한 기업들로 해보고 싶었는데, 상관계수가 작아서 시각화할 때 안 예뻐서 이 둘로 정했습니다!
# AT&T과 버라이즌의 공분산 계산
cov_av = np.cov(sp500_px_df[atnt], sp500_px_df[verizon])
print(cov_av) ''' [[0.08390944 0.05784096]
[0.05784096 0.10472254]]'''
numpy의 cov() 함수를 사용하면 두 변수 사이의 공분산 행렬을 반환합니다. (0, 0), (1, 1)은 각각 AT&T와 버라이즌의 분산을 의미하고, (0, 1), (1, 0)은 AT&T와 버라이즌의 공분산으로, 두 값은 같습니다.
Numpy를 이용해서 공분산을 계산할 때는 위의 수식과는 달리 자유도를 고려하지 않습니다. 자유도를 고려하기 위해서는 ddof변수를 1로 설정합니다.
# AT&T과 버라이즌의 상관계수 계산
corr_av = np.corrcoef(sp500_px_df[atnt], sp500_px_df[verizon])
print(corr_av) '''[[1. 0.61703529]
[0.61703529 1. ]]'''
`corrcoef()`함수를 사용하면 두 변수 사이의 상관계수 행렬을 반환합니다.<br>(0, 0), (1, 1)은 자신과의 상관계수 이므로 최대값인 1이고, (0, 1), (1, 0)은 AT&T와 버라이즌의 상관계수입니다. 두 회사는 꽤 높은 **양의 상관관계**를 갖는다고 볼 수 있습니다.
# scatterplot
ax = sns.scatterplot(data=sp500_px_df, x=atnt, y=verizon, color='r')
ax.axhline(0, color='grey', lw=1) # 수평선 추가
ax.axvline(0, color='grey', lw=1) # 수직선 추가
fig = ax.get_figure()
fig.savefig(f"{save_path}/scatter.png")
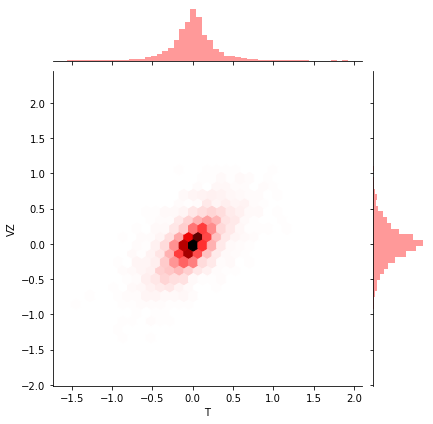
두 변수의 상관관계를 확인할 때 가장 많이 사용하는 scatterplot입니다. 한눈에 상관관계를 확인할 수 있습니다.
하지만 scatterplot은 데이터가 너무 많은 경우 점이 겹쳐 보이기 때문에, 겹쳐 보이는 부분의 밀도는 확인하기 어려운 한계가 있습니다.
아이스크림 가게 A와 B의 매출 표준 편차를 반올림하면 각각 4.54만원, 14.29만원으로, 데이터의 단위와 일치합니다.
이로써 우리는 아이스크림 가게 B의 매출이 A보다 변동성이 크다고 볼 수 있습니다. 하지만, A가 B보다 장사가 잘된다고 볼 수 없습니다.
마무리
이 글에서는 평균, 분산, 표준편차를 정리해봤습니다. 이 세가지 통계량은 데이터의 특성을 나타내주는 좋은 지표이지만, 이상치(outlier)에 민감하게 반응하는 단점이 있습니다.
가끔은 이상치에 robust한 통계량을 확인하는 것도 필요하기 때문에, 평균대신 중앙값(median), 표준편차 대신 중위절대편차(MAD)를 사용하기도 합니다.
긴 글 읽어주셔서 감사합니다. 다음 글은 두 변수 사이의 상관관계에 대해서 다루겠습니다.
좋은 하루 보내세요 :)
* 자유도를 이해하기 위해서는 분산을 계산하기 위해선 평균을 알아야한다는 것에 집중할 필요가 있습니다. $\mu$를 알고있으면, 분산을 계산할 때 반드시 $x_1$부터 $x_n$까지 순서대로 계산되지 않더라도 마지막 순서의 변수 값을 알 수 있습니다. 즉, $n-1$개의 변수는 어느 값이든 가질 수 있지만 마지막 1개의 변수는 $\mu$에 의해서 특정되기 때문에, '자유로운' 변수의 개수는 $n-1$개 이므로 자유도는 $n-1$이 됩니다. 모집단의 분산을 표본의 분산을 통해 유추하기 위해서는 위와 같이 자유도를 고려하는 것이 바람직하다고 합니다. 최근 우리가 사용하는 데이터의 수는 매우 많기 때문에 자유도를 깊게 이해하고 넘어갈 필요는 없지만, Regression(회귀)을 학습할 때 주의해야하는 다중공선성(multicollinearity)을 이해하기 위해서는 어느정도 알고 있는게 좋을 거 같습니다.